Multiclass-prediction-of-liver-cirrhosis
Multi-Class Prediction of Cirrhosis Outcomes
Project Overview
This project focuses on predicting the survival outcomes of patients with liver cirrhosis using machine learning techniques. The data, derived from a Mayo Clinic study on primary biliary cirrhosis (PBC) of the liver conducted between 1974 and 1984, includes 17 clinical features. The goal is to develop a model that accurately classifies patients into three survival categories:
- D (death)
- C (censored)
- CL (censored due to liver transplantation)
Understanding Liver Cirrhosis
What is Liver Cirrhosis?
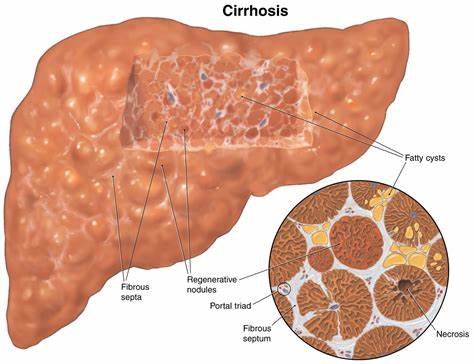 Liver cirrhosis is a chronic, degenerative condition characterized by the replacement of healthy liver tissue with scar tissue. This scarring impairs the liver’s ability to function properly and can lead to liver failure, which is life-threatening. Cirrhosis is often the end stage of chronic liver diseases, including hepatitis, fatty liver disease, and chronic alcoholism.
Liver cirrhosis is a chronic, degenerative condition characterized by the replacement of healthy liver tissue with scar tissue. This scarring impairs the liver’s ability to function properly and can lead to liver failure, which is life-threatening. Cirrhosis is often the end stage of chronic liver diseases, including hepatitis, fatty liver disease, and chronic alcoholism.
Why is Early Detection Important?
Early detection of liver cirrhosis is crucial for several reasons:
- Prevention of Progression: Early diagnosis allows for interventions that can slow or halt the progression of the disease.
- Improved Treatment Outcomes: With timely treatment, patients can manage symptoms more effectively, and in some cases, the liver damage can be partially reversed.
- Reduction in Mortality: Early detection and treatment significantly reduce the risk of liver failure and death.
- Planning for Transplantation: In cases where cirrhosis progresses to the point where the liver can no longer function, early detection can help in planning for a liver transplant, improving the chances of survival.
Current Challenges in Detection
Detecting cirrhosis in its early stages is challenging because the symptoms are often non-specific and may be attributed to other less serious conditions. As a result, many patients are diagnosed only when the disease has advanced significantly. Current methods of diagnosis include blood tests, imaging studies, and liver biopsy, but these can be invasive, costly, and sometimes inaccurate.
Importance of Machine Learning in Cirrhosis Prediction
Machine learning offers a powerful tool to improve the early detection and prediction of cirrhosis outcomes. By analyzing large datasets of clinical features, machine learning models can identify patterns and risk factors that might be missed by traditional methods. This can lead to:
- More Accurate Predictions: Machine learning models can improve the accuracy of survival predictions, helping clinicians make more informed decisions about patient care.
- Personalized Treatment Plans: By understanding the individual risk factors for each patient, treatment can be tailored to the specific needs of the patient, improving outcomes.
- Cost-Effective Screening: Automated models can be used in routine screening processes, potentially reducing the need for expensive and invasive procedures.
Future Directions
The future of cirrhosis detection and management could be significantly impacted by advances in machine learning and related technologies:
- Integration with Electronic Health Records (EHRs): Machine learning models could be integrated with EHRs to provide real-time risk assessments and decision support for clinicians.
- Development of Non-Invasive Diagnostic Tools: Research is ongoing into the use of biomarkers and imaging technologies, combined with machine learning, to develop non-invasive diagnostic tools.
- Predictive Analytics for Treatment Response: Future models could not only predict survival outcomes but also how patients are likely to respond to different treatments, enabling more personalized and effective care.
- Public Health Implications: On a larger scale, predictive models could help in identifying at-risk populations, guiding public health interventions, and allocating resources more efficiently.
Problem Statement
Cirrhosis is a degenerative liver disease that can lead to liver failure. The primary task is to predict the survival status of patients diagnosed with cirrhosis using clinical data. The survival states are classified as follows:
- 0 = D (death)
- 1 = C (censored)
- 2 = CL (censored due to liver transplantation)
Dataset Description
- Source: Mayo Clinic study on PBC of the liver (1974-1984)
- Features: 17 clinical features
- Target Variable:
Status(categorical)- C: Patient alive at N_Days (censored)
- CL: Patient alive at N_Days due to liver transplantation
- D: Patient deceased at N_Days
Files
train.csv: The training dataset containing clinical features and survival status information.test.csv: The test dataset for predicting the probability of each status value.sample_submission.csv: A sample submission file in the correct format.
Evaluation
Submissions are evaluated using the multi-class logarithmic loss. Each ID in the test set has a single true class label (Status). For each ID, you must submit a set of predicted probabilities for each of the three possible outcomes (Status_C, Status_CL, and Status_D).
The evaluation metric is calculated as follows:
[ \text{Log Loss} = -\frac{1}{N}\sum_{i=1}^{N}\sum_{j=1}^{M}y_{ij}\log(p_{ij}) ]
Where:
- (N) is the number of rows in the test set
- (M) is the number of outcomes (i.e., 3)
- (y_{ij}) is 1 if row (i) has the ground truth label (j) and 0 otherwise
- (p_{ij}) is the predicted probability that observation (i) belongs to class (j)
Methodology
- Data Preprocessing: Cleaning and transforming the dataset to ensure its suitability for modeling.
- Feature Engineering: Extracting relevant information from the dataset and creating new informative features.
- Feature Selection: Identifying the most predictive features while eliminating redundant ones to optimize model performance.
- Modeling: Training various machine learning algorithms, including XGBoost, LightGBM, and CatBoost, on the selected features.
- Ensemble Modeling: Combining predictions from multiple models to enhance predictive accuracy and robustness.
- Evaluation: Rigorous evaluation, including cross-validation and hyperparameter tuning, to ensure the model’s reliability and generalization capability.
- Testing: Assessing the model’s performance on unseen data.
Achievements
- High accuracy scores during model evaluation.
- Low log loss values, indicating minimal errors in probability estimates.
Citation
Walter Reade, Ashley Chow. “Multi-Class Prediction of Cirrhosis Outcomes.” Kaggle, 2023. [Online]. Available: https://kaggle.com/competitions/playground-series-s3e26